What Anthropic's Legal Seminar Didn't Show You - Demystifying AI in Word
Xi Sun, Co-Founder & CTO

This week Anthropic ran their Claude for Legal Teams seminar — live demos of Claude doing contract redlining, extraction, first-pass review. Clean demo. Impressed lawyers. And they recently launched Claude for Word, going directly after legal workflows.
All of this is great for the industry. But it doesn’t show the hard part — what’s actually going on underneath.
Word is not a text editor
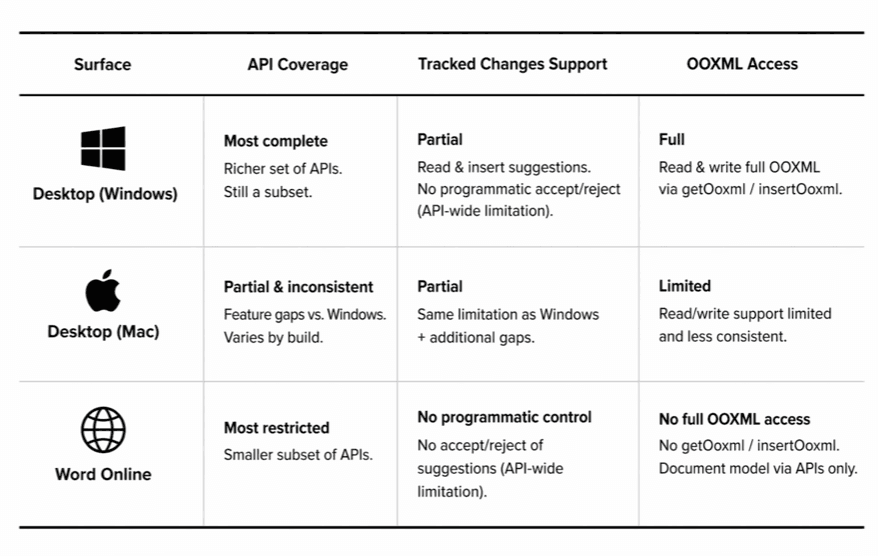
It's a 30-year-old document platform with distinct surfaces — Desktop Windows, Desktop Mac, and Word Online — each with different API coverage, different behavior, and different failure modes. Same API declaration. Wildly different runtime.
You can't write one integration and ship it everywhere. Every row in that table requires its own fallback path.
What you see is not what Word sees
Open any contract. It looks clean. One sentence: "reasonable efforts to complete the deliverables." Here's what Word actually stores for that sentence:
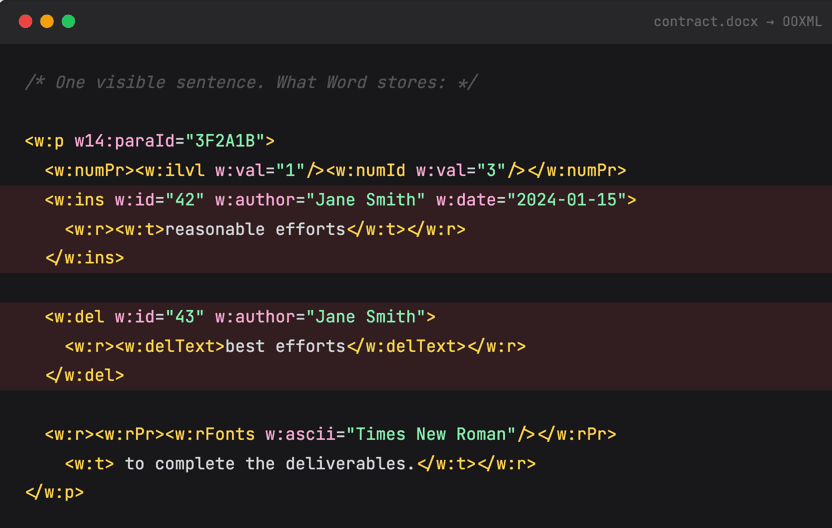
Author metadata, timestamps, insertion markers, deletion markers, font runs, numbering references, paragraph IDs — all interwoven. And that's a simple case. A real contract with two rounds of counterparty redlines looks like this multiplied by fifty.
This is not a prompt problem on the plain text. You cannot instruct a model without factoring all these metadata and data models into consideration.
And Word has no stable IDs...
Every engineer building in Word hits this: there's no universal stable identifier for content units. The w14:paraId attribute exists in OOXML but isn't reliably exposed through the API, isn't consistent across surfaces, and isn't stable across save-reload cycles.
Why vibe coding breaks here
The tempting path: build a Word add-in with an agentic tool, plug in a model, iterate until demos look good. It works until it doesn't. In legal, "until it doesn't" is a liability event — an edit that lands in the wrong clause, or overwrites what opposing counsel just agreed to.
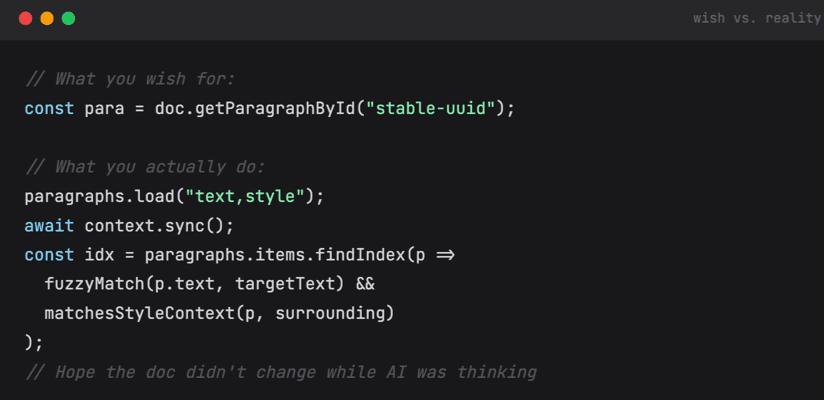
The specific trap: Word's .text property API returns visible accepted text only — stripping all tracked changes. The model reasons on a clean document, but applies edits back into a live redlined one. Ranges don't align. The edit lands in the wrong place. It looks correct. It isn't.

Word's timeout silently kills high-reasoning models
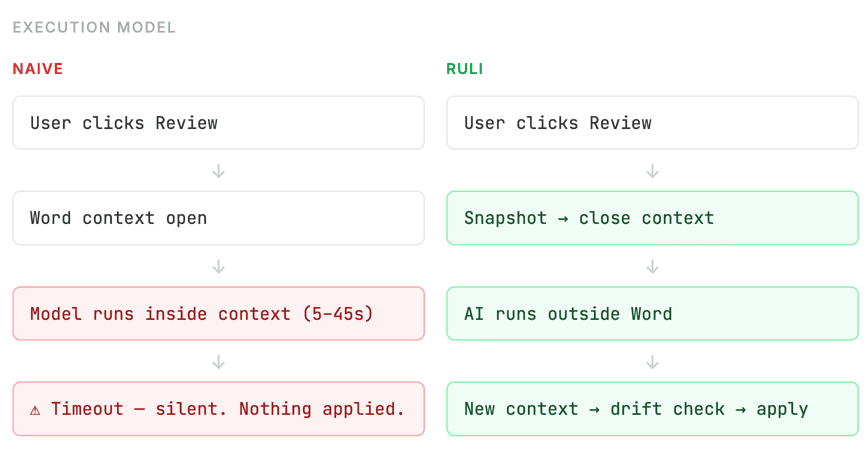
Word's Office JS API has a strict execution timeout per context sync. If your AI call takes too long — which frontier reasoning models on a 100-page contract frequently do — Word silently terminates the operation. No error. No notification. Nothing applied.
The timeout varies by surface and isn't documented clearly. You find it by hitting it in production.
How Ruli approaches it: Context Engineering in Word
The problem isn’t just generating edits — it’s working with what Word actually is. Context engineering here isn’t about retrieval. It’s about constructing a representation of the document that preserves structure, history, and intent — before anything touches the model.
Layered document view
A Word document isn’t a single stream of text. In Ruli, we engineered a sophisticated diff engine that parse the word document across multiple layers — what’s visible, what existed before, and what’s being modified — so the model reasons over both content and change. Underneath, a diff layer reconstructs how the document evolved, rather than relying on the current surface alone.
Anchoring without stable IDs
Word doesn’t provide stable identifiers for content. Edits are anchored relative to structure, then revalidated against the document state when results return. If the document shifts, alignment is rechecked before anything is applied.
Context-aware interpretation
Clauses don’t have fixed meaning — they depend on role and position in the document. We incorporate surrounding structure and party context so the model interprets text in the same way a human reviewer would.
Reasoning across documents
Documents are part of a larger negotiation flow. Prior edits and related materials inform how changes should be made, so reasoning extends beyond the current file, and can be reused via our Knowledge layer.
The real moat in legal AI isn't the model. Any serious player can access frontier models. The moat is the infrastructure between the model and Word — the document parsing, anchoring logic, layer context, and runtime management that makes it reliable at enterprise scale.
We’ve been working in this space for the past two years, things that seem trivial — like preserving styling when regenerating edits, keeping version history coherent across iterations, or giving users exactly what they want — turn out to be surprisingly hard at scale. We’re proud of the progress we’ve made at Ruli, there are still plenty of open challenges we’re actively working and improving. And we are hiring! Check out our roles on LinkedIn job page if these challenges resonate with you.
For teams exploring legal AI, the real difference shows up in how these systems behave beyond the demo. If you want to see how Ruli works in practice, you can book a demo here:👉 https://www.ruli.ai/demo
This week Anthropic ran their Claude for Legal Teams seminar — live demos of Claude doing contract redlining, extraction, first-pass review. Clean demo. Impressed lawyers. And they recently launched Claude for Word, going directly after legal workflows.
All of this is great for the industry. But it doesn’t show the hard part — what’s actually going on underneath.
Word is not a text editor
It's a 30-year-old document platform with distinct surfaces — Desktop Windows, Desktop Mac, and Word Online — each with different API coverage, different behavior, and different failure modes. Same API declaration. Wildly different runtime.
You can't write one integration and ship it everywhere. Every row in that table requires its own fallback path.
What you see is not what Word sees
Open any contract. It looks clean. One sentence: "reasonable efforts to complete the deliverables." Here's what Word actually stores for that sentence:
Author metadata, timestamps, insertion markers, deletion markers, font runs, numbering references, paragraph IDs — all interwoven. And that's a simple case. A real contract with two rounds of counterparty redlines looks like this multiplied by fifty.
This is not a prompt problem on the plain text. You cannot instruct a model without factoring all these metadata and data models into consideration.
And Word has no stable IDs...
Every engineer building in Word hits this: there's no universal stable identifier for content units. The w14:paraId attribute exists in OOXML but isn't reliably exposed through the API, isn't consistent across surfaces, and isn't stable across save-reload cycles.
Why vibe coding breaks here
The tempting path: build a Word add-in with an agentic tool, plug in a model, iterate until demos look good. It works until it doesn't. In legal, "until it doesn't" is a liability event — an edit that lands in the wrong clause, or overwrites what opposing counsel just agreed to.
The specific trap: Word's .text property API returns visible accepted text only — stripping all tracked changes. The model reasons on a clean document, but applies edits back into a live redlined one. Ranges don't align. The edit lands in the wrong place. It looks correct. It isn't.
Word's timeout silently kills high-reasoning models
Word's Office JS API has a strict execution timeout per context sync. If your AI call takes too long — which frontier reasoning models on a 100-page contract frequently do — Word silently terminates the operation. No error. No notification. Nothing applied.
The timeout varies by surface and isn't documented clearly. You find it by hitting it in production.
How Ruli approaches it: Context Engineering in Word
The problem isn’t just generating edits — it’s working with what Word actually is. Context engineering here isn’t about retrieval. It’s about constructing a representation of the document that preserves structure, history, and intent — before anything touches the model.
Layered document view
A Word document isn’t a single stream of text. In Ruli, we engineered a sophisticated diff engine that parse the word document across multiple layers — what’s visible, what existed before, and what’s being modified — so the model reasons over both content and change. Underneath, a diff layer reconstructs how the document evolved, rather than relying on the current surface alone.
Anchoring without stable IDs
Word doesn’t provide stable identifiers for content. Edits are anchored relative to structure, then revalidated against the document state when results return. If the document shifts, alignment is rechecked before anything is applied.
Context-aware interpretation
Clauses don’t have fixed meaning — they depend on role and position in the document. We incorporate surrounding structure and party context so the model interprets text in the same way a human reviewer would.
Reasoning across documents
Documents are part of a larger negotiation flow. Prior edits and related materials inform how changes should be made, so reasoning extends beyond the current file, and can be reused via our Knowledge layer.
The real moat in legal AI isn't the model. Any serious player can access frontier models. The moat is the infrastructure between the model and Word — the document parsing, anchoring logic, layer context, and runtime management that makes it reliable at enterprise scale.
We’ve been working in this space for the past two years, things that seem trivial — like preserving styling when regenerating edits, keeping version history coherent across iterations, or giving users exactly what they want — turn out to be surprisingly hard at scale. We’re proud of the progress we’ve made at Ruli, there are still plenty of open challenges we’re actively working and improving. And we are hiring! Check out our roles on LinkedIn job page if these challenges resonate with you.
For teams exploring legal AI, the real difference shows up in how these systems behave beyond the demo. If you want to see how Ruli works in practice, you can book a demo here:👉 https://www.ruli.ai/demo