Demystifying AI Legal Research: Why Ruli Continues to Win Over General AI Tools
Xi Sun, Co-Founder & CTO

When legal teams compare AI vendors, they often ask: “Why does Ruli’s research feel more grounded and reliable than what we get from general tools like ChatGPT or Claude? What’s actually happening under the hood?”
The answer starts with a common misconception, that legal research can be solved with “a smart model and the right prompt.” That impression holds if your reference point is a general-purpose LLM: you ask a question, it returns a polished paragraph, and the workflow appears simple.
Legal research is not a single-step generation task. It’s a pipeline: identifying the issue, retrieving governing authority, weighing jurisdictional relevance, applying rules to facts, and supporting conclusions with verifiable citations. Any system that collapses this into one model call will miss authority, hallucinate citations, or produce inconsistent analysis.
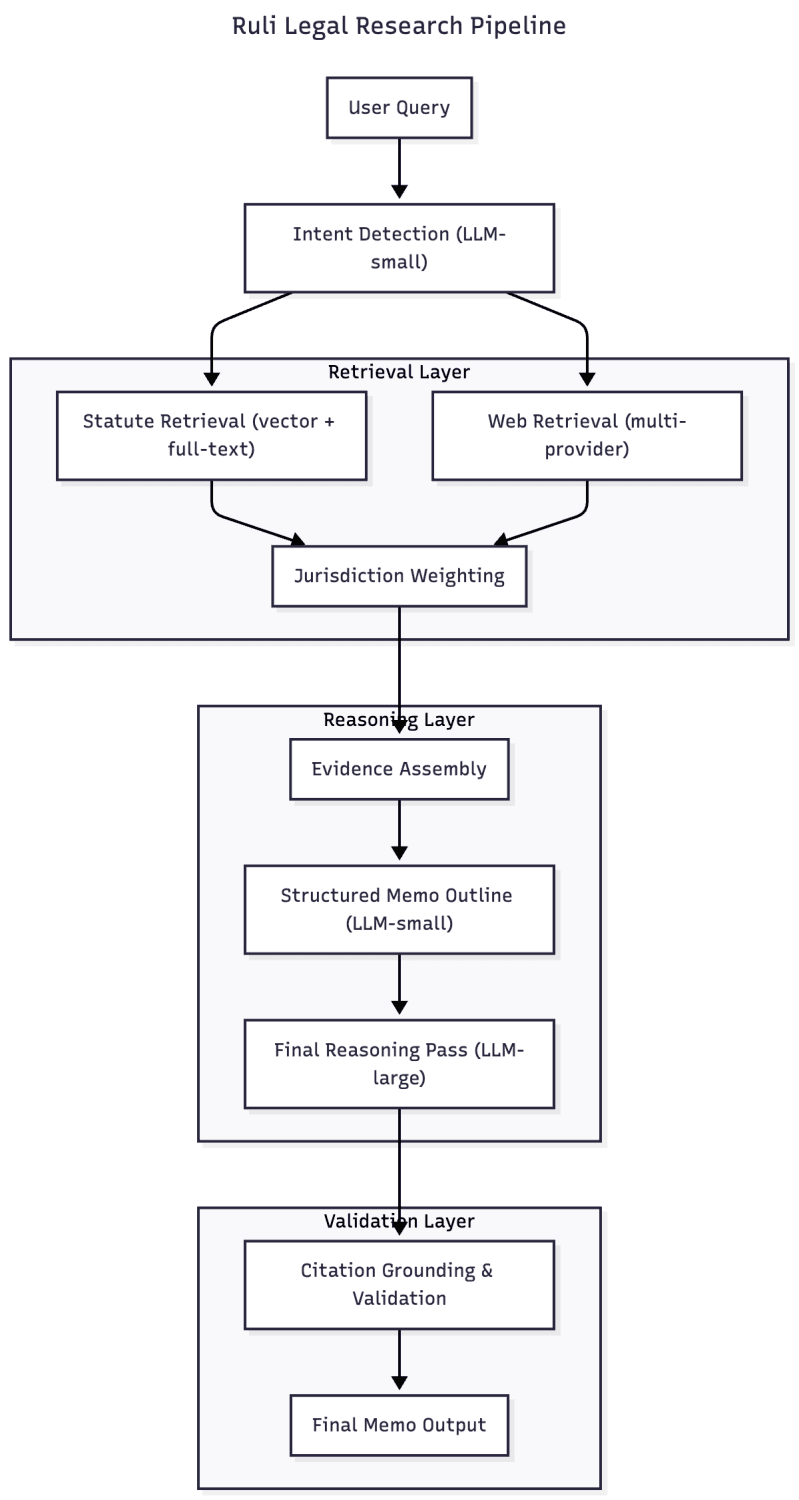
Ruli avoids those failure modes by design. Instead of relying on a single model pass, it orchestrates a retrieval–>reasoning–>validation workflow that mirrors how legal analysis is actually performed. This pipeline-first architecture is the core reason Ruli behaves so differently from general-purpose AI tools during evaluations.
1. Retrieval First: Grounding the System in Actual Law
General AI tools primarily rely on model memory, which produces smooth prose but doesn’t guarantee legal accuracy. Ruli starts with retrieval instead. The system queries a hybrid vector and full-text index containing statutory and regulatory materials, then supplements that with controlled web retrieval from high-credibility legal sources.
Several engineering concerns show up here: statutory text must be segmented into consistent chunks; embeddings must be updated as laws change; vector indices must serve semantic matches at low latency; and multiple external search providers must be orchestrated with fallback behavior. The output of this stage is a structured evidence set, not a generated answer.
Retrieval-first design ensures that all downstream reasoning is grounded in actual authority, not inference from training data.
2. Structured Reasoning: Analysis With Constraints
After retrieval, Ruli generates a memo outline before producing any narrative text. This outline identifies issues, rules, and jurisdictional distinctions, and it specifies the analytical structure the reasoning model must follow.
The outline phase stabilizes the system. It reduces variance, prevents the model from drifting into irrelevant topics, and enforces a consistent analytical structure for the final reasoning step. It also allows the system to handle very long contexts (often hundreds of thousands of tokens) in a controlled, predictable way. The result is output that follows the same structure and clarity lawyers expect in real legal work product.
3. Tiered LLM Architecture: Separating Fast Tasks From Deep Reasoning
Ruli does not use a single large model for all tasks. Different stages require different computational profiles.
Smaller models handle fast operations such as intent classification, jurisdiction inference, query rewriting, and extraction of key terms. These tasks benefit from high speed and predictable cost, and they don’t require deep reasoning.
Larger models are reserved for the final reasoning pass. By the time they are invoked, the system has already assembled a curated, jurisdiction-aware evidence bundle. The large model is responsible only for synthesizing that material into coherent analysis. It is not responsible for finding sources or interpreting unfiltered text.
This separation improves throughput, reduces hallucinations, and ensures that the heavy model is used only when its advanced reasoning capacity is genuinely required.
4. Citation Grounding and Validation: Making Outputs Verifiable
General-purpose LLMs frequently produce fabricated citations because they have no built-in mechanism for tracking source provenance. Ruli adds that mechanism explicitly.
After generating the draft, a validation stage inspects each citation tag, ensures it maps to a real retrieved source, checks ordering, and constructs a reference list grouped by authority type. The interface exposes these sources to the user, linking each citation to the underlying text.
From an implementation standpoint, this requires consistent metadata propagation across the pipeline and reconciliation logic that can detect mismatches between model output and retrieved material. The result is analysis that can be inspected and verified, not just read.
5. Engineering for Scale and Reliability
A full research run involves multiple subsystems: statute retrieval, web search, vector queries, document ranking, model tiering, outline generation, long-context reasoning, and citation validation. Each component has its own failure modes, and the system must degrade gracefully when any of them slow down or produce incomplete results.
To maintain reliability, Ruli incorporates parallel retrieval, caching of statutory and web content, token-budgeting algorithms for large authorities, fallback logic when providers degrade, and consolidated model calls to reduce latency. Observability is built into each stage so that issues can be identified and corrected without affecting correctness.
General AI tools skip nearly all of this complexity because they were not built for legal research workloads. Ruli was designed for them from the start.
Building reliable AI legal research isn’t just a prompt-design problem. The systems behind Ruli were built to handle retrieval, reasoning, validation, and scale in a way general-purpose LLMs weren’t designed for.
We’re continuing to hire engineers who want to work on these challenges. If your team wants to see how this research pipeline operates end-to-end, you can book a demo to explore it in practice.
When legal teams compare AI vendors, they often ask: “Why does Ruli’s research feel more grounded and reliable than what we get from general tools like ChatGPT or Claude? What’s actually happening under the hood?”
The answer starts with a common misconception, that legal research can be solved with “a smart model and the right prompt.” That impression holds if your reference point is a general-purpose LLM: you ask a question, it returns a polished paragraph, and the workflow appears simple.
Legal research is not a single-step generation task. It’s a pipeline: identifying the issue, retrieving governing authority, weighing jurisdictional relevance, applying rules to facts, and supporting conclusions with verifiable citations. Any system that collapses this into one model call will miss authority, hallucinate citations, or produce inconsistent analysis.
Ruli avoids those failure modes by design. Instead of relying on a single model pass, it orchestrates a retrieval–>reasoning–>validation workflow that mirrors how legal analysis is actually performed. This pipeline-first architecture is the core reason Ruli behaves so differently from general-purpose AI tools during evaluations.
1. Retrieval First: Grounding the System in Actual Law
General AI tools primarily rely on model memory, which produces smooth prose but doesn’t guarantee legal accuracy. Ruli starts with retrieval instead. The system queries a hybrid vector and full-text index containing statutory and regulatory materials, then supplements that with controlled web retrieval from high-credibility legal sources.
Several engineering concerns show up here: statutory text must be segmented into consistent chunks; embeddings must be updated as laws change; vector indices must serve semantic matches at low latency; and multiple external search providers must be orchestrated with fallback behavior. The output of this stage is a structured evidence set, not a generated answer.
Retrieval-first design ensures that all downstream reasoning is grounded in actual authority, not inference from training data.
2. Structured Reasoning: Analysis With Constraints
After retrieval, Ruli generates a memo outline before producing any narrative text. This outline identifies issues, rules, and jurisdictional distinctions, and it specifies the analytical structure the reasoning model must follow.
The outline phase stabilizes the system. It reduces variance, prevents the model from drifting into irrelevant topics, and enforces a consistent analytical structure for the final reasoning step. It also allows the system to handle very long contexts (often hundreds of thousands of tokens) in a controlled, predictable way. The result is output that follows the same structure and clarity lawyers expect in real legal work product.
3. Tiered LLM Architecture: Separating Fast Tasks From Deep Reasoning
Ruli does not use a single large model for all tasks. Different stages require different computational profiles.
Smaller models handle fast operations such as intent classification, jurisdiction inference, query rewriting, and extraction of key terms. These tasks benefit from high speed and predictable cost, and they don’t require deep reasoning.
Larger models are reserved for the final reasoning pass. By the time they are invoked, the system has already assembled a curated, jurisdiction-aware evidence bundle. The large model is responsible only for synthesizing that material into coherent analysis. It is not responsible for finding sources or interpreting unfiltered text.
This separation improves throughput, reduces hallucinations, and ensures that the heavy model is used only when its advanced reasoning capacity is genuinely required.
4. Citation Grounding and Validation: Making Outputs Verifiable
General-purpose LLMs frequently produce fabricated citations because they have no built-in mechanism for tracking source provenance. Ruli adds that mechanism explicitly.
After generating the draft, a validation stage inspects each citation tag, ensures it maps to a real retrieved source, checks ordering, and constructs a reference list grouped by authority type. The interface exposes these sources to the user, linking each citation to the underlying text.
From an implementation standpoint, this requires consistent metadata propagation across the pipeline and reconciliation logic that can detect mismatches between model output and retrieved material. The result is analysis that can be inspected and verified, not just read.
5. Engineering for Scale and Reliability
A full research run involves multiple subsystems: statute retrieval, web search, vector queries, document ranking, model tiering, outline generation, long-context reasoning, and citation validation. Each component has its own failure modes, and the system must degrade gracefully when any of them slow down or produce incomplete results.
To maintain reliability, Ruli incorporates parallel retrieval, caching of statutory and web content, token-budgeting algorithms for large authorities, fallback logic when providers degrade, and consolidated model calls to reduce latency. Observability is built into each stage so that issues can be identified and corrected without affecting correctness.
General AI tools skip nearly all of this complexity because they were not built for legal research workloads. Ruli was designed for them from the start.
Building reliable AI legal research isn’t just a prompt-design problem. The systems behind Ruli were built to handle retrieval, reasoning, validation, and scale in a way general-purpose LLMs weren’t designed for.
We’re continuing to hire engineers who want to work on these challenges. If your team wants to see how this research pipeline operates end-to-end, you can book a demo to explore it in practice.